MDB-02 Data Modelling
On This Page
Key Features of MongoDB
- Schema-less design allows you to store data in JSON-like format.
- Scalability: MongoDB supports horizontal scaling through sharding, making it efficient for big data.
- High Performance: Designed for fast reads and writes with indexes and in memory capabilities.
- Replication: Provides data redundancy and high availability
Documents
- Documents in MongoDB are the primary unit of storage, and each document is represented as a BSON object.
- A document contains key-value pairs and can store complex data types like arrays and embedded documents.
- The
_idfield is a unique identifier automatically generated for each document
{
"_id": 1,
"name": “Pranav",
"address": {
"street": "123 Elm St",
"city": "Somewhere",
}
}Collection
- A collection is like a whole notebook that holds many pages (documents) about a specific topic.
- In MongoDB, documents that are similar are grouped together in a collection.
- Example: You might have a collection called "Pets" that contains all the documents for each of your pets
Schema Design
- MongoDB allows you to store data without a fixed schema, meaning documents in a collection can have different structures.
- Schema Design Considerations:
- Denormalization: Embed related data in a single document. This improves performance when reading, but increases the document size.
- Normalization: Store data in separate collections and link them using references. This reduces redundancy but may lead to more complex queries.
- Performance: Design schemas to optimize query performance based on read and write patterns.
Embedded Documents
- In embedding, the related data is stored within the same document as a nested structure.
- Use this approach when data is closely related and usually accessed together.
- Advantages: Faster read operations, simpler schema.
{
"_id": 1,
"name": "Amit Sharma",
"age": 16,
"address": {
"street": "MG Road",
"city": "Ahmedabad",
"pincode": "380015"
}
}References
- Use when data is large, or there is a many-to-one or many-to-many relationship.
- In referencing, related data is stored in separate documents, and a reference (usually an
_id) is used to link them - Advantages: Avoids document duplication and reduces storage requirements.
{
"_id": 1,
"name": "Amit Sharma",
"age": 16,
"address_id": 101
}- Here, the
address_idin the student's document references the_idof the address document in the Addresses collection. To get the complete information about a student, you would need to join or query both collections.
Embedded vs References
| Aspect | Embedding | Referencing |
|---|---|---|
| Srtucture | Nested data within the same document | Related data stored separately |
| Performance | Faster reads, fewer queries | Slower reads due to joins |
| Data Duplication | May lead to duplication | Reduces duplication |
| Flexibility | Harder to u date shared data | Easier to update shared data |
| Use Case | Simple, closely related data | Complex, reusable data |
MongoDb Data Structures
- Database: A container for collections.
- Collection: A group of documents, equivalent to a table in relational databases.
- Document: A set of key-value pairs, analogous to a row in relational databases. Documents are stored in BSON (Binary JSON) format
Querying MongoDB
- MongoDB Query Language (MQL) allows you to query collections in a rich and flexible manner.
db.collection.find({query})- The query returns documents that match the specified criteria.
Comparison Operator
$eq: Matches values that are equal to a specified value.
db.emp.find({ deptname: { $eq: "IT" } })$ne: Matches values that are not equal.
db.emp.find({ deptname: { $ne: "IT" } })$gt: Matches values greater than a specified value.
db.emp.find({ salary: { $gt: 80000 } })$lt: Matches values less than a specified value.
db.emp.find({ salary: { $lt: 80000 } })$gte: Matches values greater than or equal to.
db.emp.find({ empid: { $gte: 22 } })$lte: Matches values less than or equal to
db.emp.find({ empid: { $lte: 5 } })$in: Allows you to match documents where a field’s value is within a specified array
db.emp.find({ empid: { $in: [1,3,5,8] } })$nin: Selects those documents where the field value is not equal to any of the given values in the array and the field that does not exist.
db.emp.find({ empid: { $nin: [1,3,5,8] } })Logical Operator
$and: Joins query clauses with a logical AND
db.emp.find({ $and: [ { deptname: "Sales" }, { salary: { $gt: 40000 } } ] })$or: Joins query clauses with a logical OR
db.emp.find({ $or: [ { deptname: "HR" }, { salary: { $lt: 30000 } } ] }$not: Inverts the effect of a query expression.
db.emp.find({ city: { $not: { $regex: "^B" } } })$nor: Joins query clauses with a logical NOR.
db.emp.find({$nor: [{salary: 3000}, {deptname: "IT"}]})distinct
db.emp.distinct(“deptname")Element Operator
$exists: Matches documents that have the specified field.
db.emp.find({ gender: { $exists: true } })$type: Selects documents if a field is of the specified type.
db.emp.find({ salary: { $type: "number" } })Projection Operator
- Retrieve only the name and age fields for all documents.
db.students.find({}, { name: 1, age: 1 })- Exclude the address field from the results
db.students.find({}, { address: 0 })- By default, MongoDB includes the
_idfield. To exclude it:
db.students.find({}, { _id: 0, name: 1, age: 1 })CRUD Operations
- MongoDB is a NoSQL database that stores data in a flexible, JSON-like format called BSON (Binary JSON)
- It is known for its scalability, high performance, and rich querying capabilities.
- CRUD stands for Create, Read, Update, and Delete.
- These are the basic operations you can perform on data in a MongoDB database.
Create Operation
- To insert a document into a collection, use the
insertOne()orinsertMany()methods.
// Switch to a database
use school// Insert a single document
db.students.insertOne({
name: "John Doe",
age: 21,
department: "Computer Science"
})// Insert multiple documents
db.students.insertMany([
{ name: "Jane Doe", age: 22, department: "Mathematics" },
{ name: "Sam Smith", age: 20, department: "Physics" }
])Read Operation
- To retrieve documents from a collection, use the
find()method.
// Find all documents in the students collection
db.students.find()// Find a document with a specific condition
db.students.find({ age: 21 })// Find documents and format the output
db.students.find({}, { name: 1, _id: 0 })Update Operation
- To update documents, use the
updateOne(),updateMany()methods.
// Update a single document
db.students.updateOne(
{ name: "John Doe" },
{ $set: { age: 22 } }
)// Update multiple documents
db.students.updateMany(
{ department: "Physics" },
{ $set: { department: "Astrophysics" } }
)Delete Operation
- To delete documents, use the
deleteOne()ordeleteMany()methods
// Delete a single document
db.students.deleteOne({ name: "Sam Smith" })// Delete multiple documents
db.students.deleteMany({ age: { $lt: 21 } })Aggregation Framework
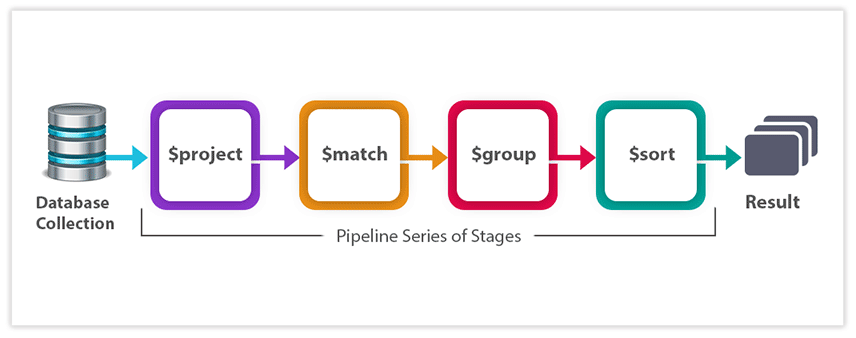
- The Aggregation Framework in MongoDB is a powerful tool used for processing and analyzing data.
- It allows you to transform and summarize data in a collection through a series of stages.
- Each stage in an aggregation pipeline performs a specific operation on the input documents and passes the result to the next stage.
- The output of the final stage is the result of the aggregation.
Basic Stages of Aggregation
-
$match: Filters the documents to pass only those that match the specified condition. -
$group: Groups input documents by a specified identifier and applies accumulator expressions. -
$project: Shapes the documents by including or excluding fields. -
$sort: Sorts the documents in ascending or descending order. -
$limit: Limits the number of documents passed to the next stage. -
$skip: Skips over a specified number of documents. -
Let's consider a sales collection that contains documents about sales transactions.
use storedb.sales.insertMany([
{ item: "apple", quantity: 10, price: 5, date: new Date("2023-01-01")},
{ item: "banana", quantity: 5, price: 2, date: new Date("2023-01-02")},
{ item: "orange", quantity: 8, price: 3, date: new Date("2023-01-03")},
{ item: "apple", quantity: 3, price: 5, date: new Date("2023-01-04")},
{ item: "banana", quantity: 7, price: 2, date: new Date("2023-01-05")}
])- Using
$match:
// Filter sales of apples
db.sales.aggregate([
{ $match: { item: "apple" } }
])- Using
$group:
// Group sales by item and calculate the total quantity sold:
db.sales.aggregate([
{ $group: { _id: "$item", totalQuantity: { $sum: "$quantity" } } }
])- Using
$project:
// Project only the item and total cost (quantity * price):
db.sales.aggregate([
{ $project: { item: 1, totalCost: { $multiply: ["$quantity", "$price"]}, _id: 0 } }
])- Using
$sort:
// Sort items by total quantity in descending order:
db.sales.aggregate([
{ $group: { _id: "$item", totalQuantity: { $sum: "$quantity" } } },
{ $sort: { totalQuantity: -1 } }
])- Using
$limit:
// Limit the result to the top 2 items with the highest total quantity:
db.sales.aggregate([
{ $group: { _id: "$item", totalQuantity: { $sum: "$quantity" } } },
{ $sort: { totalQuantity: -1 } },
{ $limit: 2 }
])- Using
$skip:
// Skip the first item and display the next one:
db.sales.aggregate([
{ $group: { _id: "$item", totalQuantity: { $sum: "$quantity" } } },
{ $sort: { totalQuantity: -1 } },
{ $skip: 1 },
{ $limit: 1 }
])Use Cases of MongoDB Aggregation
- Reporting: MongoDB’s aggregation framework can be used for generating complex reports, like calculating total sales per region, or average order value.
- Data Transformation: Use aggregation to reshape data into the desired format.
- Analytics: Useful in data analytics to derive insights from raw data, e.g., finding the most popular products in an e-commerce store.
Resources
- MongoDB Official Documentation
- MongoDB Official Course
- MongoDB 1 hour Crash Course
- MongoDB 1 hour Crash Course (English)