MDB-03 Indexing Concepts
On This Page
Indexing
- An index is a data structure that improves the speed of data retrieval operations on a database at the cost of additional space and increased maintenance overhead during data modification operations.
- In MongoDB, indexes help optimize queries, reduce the need for full collection scans, and improve performance.
- Use indexes on fields that are frequently queried, particularly those involved in sorting, filtering, and joining.
Single Field Index
- The simplest index, created on a single field in a collection.
- Single field indexes are particularly helpful when you frequently query or sort by a specific field.
- The
1in thecreateIndex()ascending order, while-1method would specifies specify descending order.
db.emp.createIndex({ "empid": 1 })- To fetch all the indexes
db.emp.getIndexes()- To drop index
db.emp.dropIndexes("empid_1")Compound Field Index
- An index created on multiple fields.
- It allows more complex queries to be optimized.
- This type of index is useful when your queries involve multiple fields, allowing MongoDB to optimize queries that reference more than one field in the condition.
db.emp.createIndex({ "deptname": 1, "salary": 1 })Multikey Index
- Used for indexing arrays.
- MongoDB creates an index for each element in the array.
- This allows MongoDB to efficiently query documents based on array elements.
{
"_id": 1,
"book": "The Courageous Journey",
"authors": ["Rajesh Kumar", "Priyanka Sharma"]
}db.books.createIndex({authors:1})Text Index
- Supports text search operations, allowing text-based queries.
- Creates a text index for all string fields.
{
"_id": ObjectId,
"name": String,
"description": String,
"category": String,
"price": Number,
"tags": [String]
}- To create a text index on all string fields in this collection, we would use the following command:
db.products.createIndex({ "$**": "text" })Geospatial Index
- Imagine you're building a location-based service where users can search for nearby places.
- Each place has a geographical location represented by latitude and longitude coordinates.
- To use a
2dsphereindex (which allows you to perform geospatial queries like finding nearby locations
db.places.insertMany([
{ name: "Cafe A", location: { type: "Point", coordinates: [40.7128, -74.0060] } }, // New York City
{ name: "Cafe B", location: { type: "Point", coordinates: [34.0522, -118.2437] } }, // Los Angeles
{ name: "Cafe C", location: { type: "Point", coordinates: [51.5074, -0.1278] } } // London
])db.places.createIndex({ location: "2dsphere" })db.places.find({
location: {
$nearSphere: {
$geometry: { type: "Point", coordinates: [40.7128,-74.0060] },
$maxDistance: 1000000 // In meters, e.g., 1,000 km radius
}
}
})Strategies for Query Optimization
- Effective Indexing:
- Identify frequently queried fields
- Determine which fields are used most often in your queries
- Create indexes on those fields: Indexes are sorted data structures that significantly speed up data retrieval.
db.emp.createIndex({ "empid": 1 })-
Craft Efficient Filters:
- Simplify them where possible
- Use operators like
$eq(equality),$gt,$lt(range comparisons), and$into narrow down the search results. - Avoid overly complex filters like nested
$orand$notoperators can degrade performance. - Excessive use of regular expressions can impact query
-
Optimize Projections:
- Retrieve only necessary fields.
- Use the projection option to specify which fields to return in the query results. This reduces data transfer and improves query speed.
db.emp.find({}, {eno:1,ename:1})- Limit Query Results:
- If you only need a subset of results, use
limit()to restrict the number of documents returned. - This can significantly reduce processing time and network overhead.
- If you only need a subset of results, use
db.emp.find().limit(3)-
Utilize the Explain Plan:
- Use the
explain()output to pinpoint areas for improvement in your queries and indexes. - The
explain()method provides detailed information about how MongoDB executes a query, including index usage, scan counts, and execution time. - Use the
explain()method to analyze query execution plans, identify bottlenecks, and optimize query performance.
- Use the
-
Consider Aggregation Framework:
- For intricate queries involving grouping, filtering, and data transformation, framework. utilize the aggregation It can often be more efficient than multiple individual queries.
db.emp.aggregate([{
$group: {
_id: "$deptname",
totalEmployees: { $sum: 1 }
}
}])-
Sharding for Large Datasets:
- For massive datasets, consider sharding to distribute data across multiple servers.
- Sharding is the process of splitting data across multiple servers (shards) to distribute the load.
- This improves read/write performance and scalability.
-
Caching:
- Implement caching mechanisms to store frequently accessed data in memory.
- Implement caching mechanisms to store frequently accessed data in memory, reducing the number of database hits and improving response times
-
Data Modelling:
- A well-designed schema can significantly impact query performance.
- Consider factors like data relationships and data types
- Design your schema carefully to minimize data redundancy and improve query performance
-
Continuous Monitoring and Refinement:
- Monitor slow queries and analyze query logs to identify areas for optimization.
- As your application evolves, adjust your indexing strategy and query patterns accordingly
- Monitor database performance metrics like CPU usage, memory consumption, and query execution times to identify potential issues.
- Perform regular maintenance tasks like data compaction, index optimization, and database backups to ensure optimal performance.
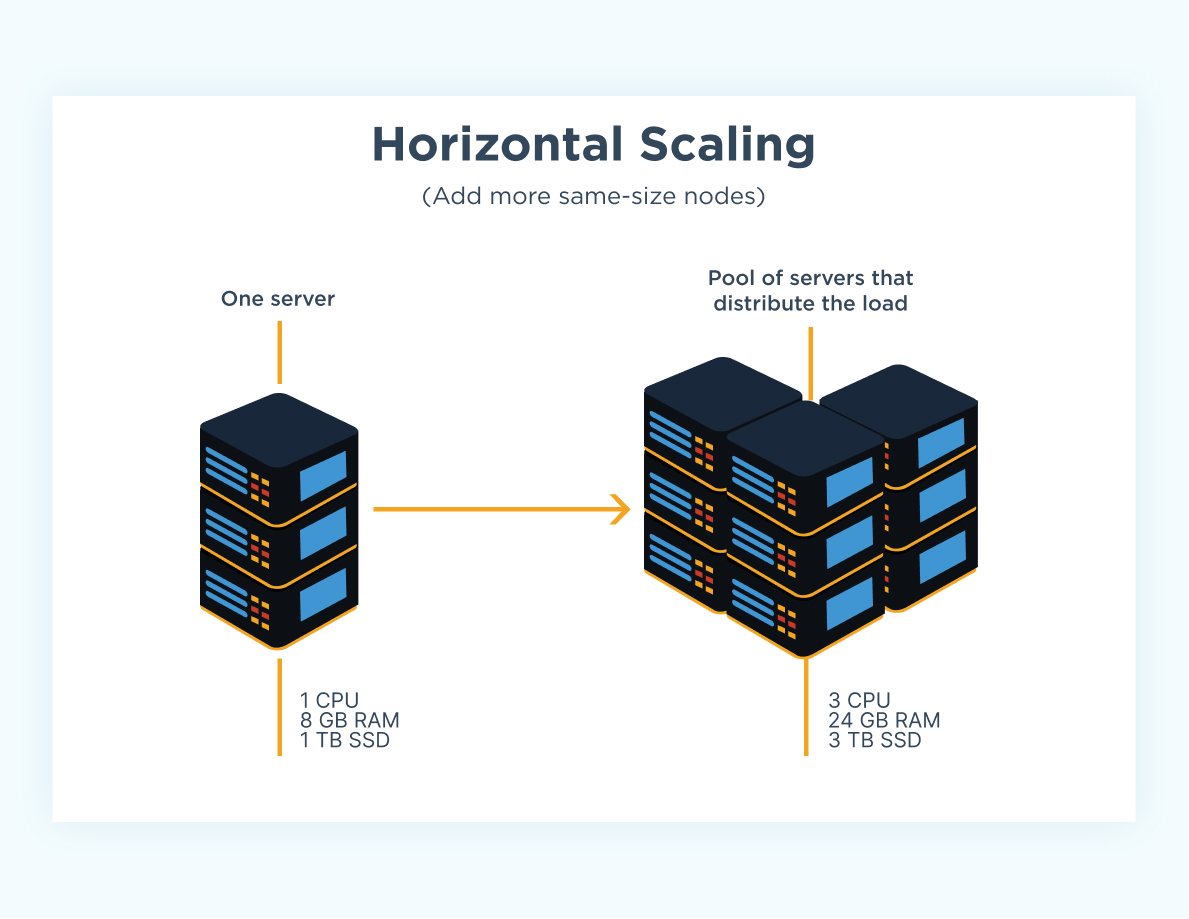
Sharding
-
Sharding helps you manage very large datasets that won't fit on a single machine.
-
Sharding is used when your data becomes too large to fit on a single server.
-
Instead of storing all the data on one machine, sharding divides the data into chunks and spreads those chunks across multiple machines (called shards)
-
By spreading the data across multiple machines, MongoDB can process queries faster, as it only needs to search through a portion of the data on each machine.
-
It's like splitting up a huge file into smaller pieces and storing those pieces on different computers so that each computer can work on a part of the file.
-
Sharding allows you to add more machines (shards) as your data grows, helping the database handle more traffic.
-
Example:
- Imagine you have a database for an online store with millions of orders.
- You could shard the data by the
order_id(shard key). - MongoDB will then divide your orders into chunks, with each chunk containing orders with a certain range of
order_ids. - These chunks are distributed across multiple shards (servers).
-
When to use?
- When you need to scale horizontally to handle large amounts of traffic and data.
- When you want to distribute workloads across multiple servers to improve performance.
Components of Sharding
- Shards: Individual servers that store parts of the data set.
- Shard Key: A field in the data that MongoDB uses to split and distribute the data.
- Chunks: Data is split into smaller ranges (chunks) and stored across different shards.
- Mongos: The routing service that directs queries to the right shard based on the shard key.
- Config Servers: Servers that store metadata and track where each chunk is stored.
Chunks and Operations
-
Split: Split key range into tow key ranges when size of chunk is too big
-
Migrate: To maintain balance migrate chunk from one shard to another.
-
Selection of Shard Key:
- It’s important to choose a shard key carefully because the performance of your application can depend on it.
- The key should be chosen in such a way that it is commonly used in queries, ensuring even distribution of data across shards, and enabling efficient query execution.
-
Characteristics of a Good Shard Key:
- The shard key should be frequently used in queries.
- A good shard key should have a large number of distinct values.
- If your queries often use range conditions (like greater than, less than, etc.), the shard key should support such operations.
-
Single Field Shard Key: Use when one field is frequently used in queries.
{
"empid": 101,
"Joindate": "2024-01-15",
"salary": 50000
}- Compound Shard Key: Use when queries filter on multiple fields together. This allows MongoDB to distribute data more evenly and efficiently route queries involving multiple fields.
{
" id": 1,
"customer. id": 101,
"2e24-ø1-15",
"amount": 500,
"status": "shipped,
}Sharding Process
- Config servers: Small
mongodswhere metadata of clusters are stored. mongos: clients connect to view whole cluster as single entity.mongod: Process for data store.
Replica Sets vs Sharding
| Aspect | Replica Set | Sharding |
|---|---|---|
| Purpose | Makes copies of data to keep it safe and available. | Helps to spread data across many computers. |
| How it Works | Makes copies of the same data on different computers. | Splits data into smaller parts and stores them on different computers |
| When to Use | When you want to make sure your data is always safe, even if one computer breaks. | When you have a lot of data that’s too big for one computer. |
| Good for | Keeping data safe, so if one computer breaks, you can still get your data | Handling huge amounts of data and keeping everything fast. |
| Challenges | Needs extra space because it keeps copies of the data | Can be tricky to set up, especially deciding how to split the data. |
| Example | Keeping copies of important school data in case your main computer crashes. | A big online store that needs to split customer orders across many computers. |
Authentication and Authorization
- Authentication is like showing your ID card or password to prove who you are. It's about checking if you're really you.
- Example: It's like showing your ID to prove who you are.
- Authorization is about deciding what you are allowed to do once you're proven to be who you are.
- Example: After logging into your game, being allowed to play certain levels based on your rank.
Encryption
- MongoDB offers two main types of encryption: at rest and in transit.
- Encryption at rest shields your data when it’s stored on disk
- While Encryption in transit secures it during transmission between your MongoDB servers and clients
Questions
- Explain the different types of indexes available in MongoDB and their use cases.
- How does indexing improves the performance of queries in MongoDB? Illustrate with an example.
- What is the role of
explain()in query optimization? Demonstrate its usage with an example. - Discuss the difference between single-field indexes and compound indexes in MongoDB.
- Differentiate between replica sets and sharding in MongoDB deployment.