MLDNN-01 Foundations of Machine Learning
On This Page
What is Artificial Intelligence (AI)
- Artificial Intelligence refers to the ability of a machine or computer system to simulate human intelligence. It allows machines to analyze data, recognize patterns, learn from past experiences, and make decisions. AI systems can improve their performance over time as they are exposed to more data.
Goals of Artificial Intelligence
1. To create intelligent machines
- The main goal of AI is to develop machines that can perform tasks intelligently, similar to human thinking and behavior.
2. To enable learning from experience
- AI aims to create systems that can learn from past data and experiences and improve automatically without explicit programming.
3. To reduce human effort
- AI helps automate repetitive and complex tasks, reducing human workload and increasing efficiency.
4. To improve decision making
- AI supports faster and more accurate decision-making by analyzing large amounts of data and identifying useful patterns.
Real-Life Applications of Artificial Intelligence
1. Healthcare
- AI is used in medical diagnosis, disease prediction, medical imaging, drug discovery, and virtual health assistants.
2. Education
- AI is applied in personalized learning systems, online tutoring platforms, automated grading, and student performance analysis.
3. Banking and Finance
- AI is used for fraud detection, credit scoring, risk analysis, and customer service chatbots.
4. Transportation
- AI plays an important role in self-driving cars, traffic prediction, route optimization, and smart transportation systems.
5. E-commerce and Marketing
- AI is used for product recommendations, customer behavior analysis, targeted advertising, and demand forecasting.
6. Communication and Entertainment
- AI is used in voice assistants, speech recognition, language translation, and content recommendation systems.
Differentiate between Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL)
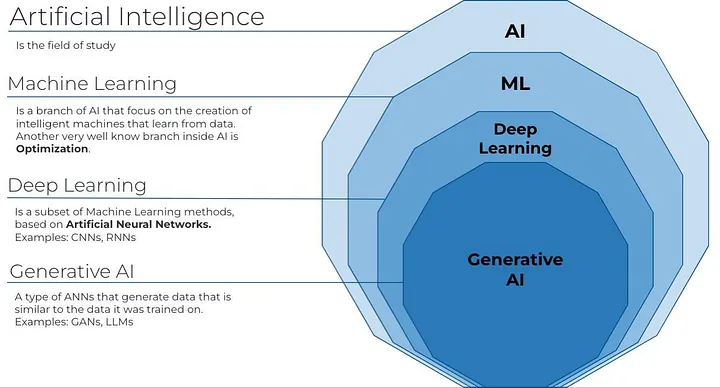
Artificial Intelligence (AI)
- Artificial Intelligence is the broad field of computer science that focuses on creating machines capable of performing tasks that normally require human intelligence such as reasoning, problem-solving, decision-making, and understanding language.
- AI can work using rule-based systems, logical reasoning, or learning techniques.
- It does not always require large amounts of data.
- Example: A rule-based expert system used in medical diagnosis or a basic chatbot that responds using predefined rules.
Machine Learning (ML)
- Machine Learning is a subset of Artificial Intelligence that enables machines to learn from data and improve their performance automatically without being explicitly programmed.
- ML focuses on identifying patterns in data and making predictions based on past experiences.
- It requires data for training and testing the model.
- Example: Email spam detection, house price prediction, and product recommendation systems.
Deep Learning (DL)
- Deep Learning is a subset of Machine Learning that uses artificial neural networks with multiple layers to learn from large and complex datasets.
- It automatically extracts important features from raw data without manual intervention.
- It requires high computational power and large volumes of data.
- Example: Face recognition systems, speech recognition, and self-driving cars.
Types of Machine Learning
- Machine Learning is a branch of Artificial Intelligence that enables systems to learn from data and improve their performance without being explicitly programmed. Based on how the data is provided and how learning happens, Machine Learning is mainly divided into three types: Supervised Learning, Unsupervised Learning, and Reinforcement Learning.
Supervised Learning
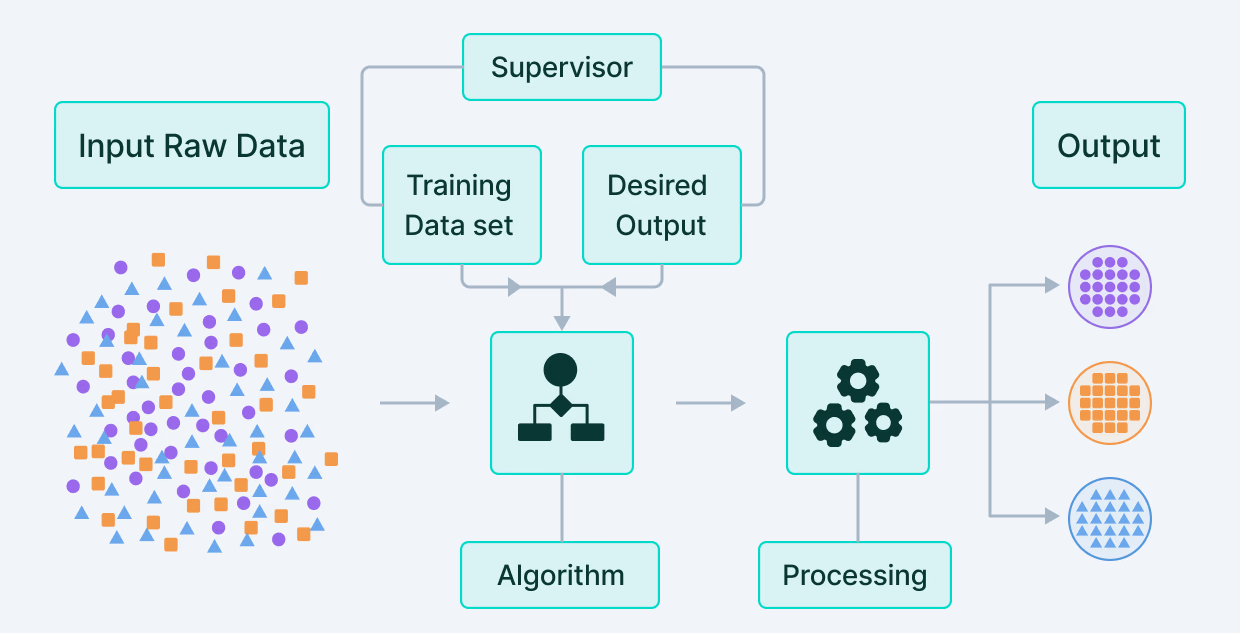
- Supervised Learning is a type of Machine Learning where the model is trained using labeled data. In this method, both input data and the correct output are provided during training.
- The model learns the relationship between input features and output labels. It then uses this learned relationship to predict outputs for new, unseen data.
- Example: Predicting whether a student will pass or fail based on study hours, or detecting whether an email is spam or not.
How it Works
- A dataset containing input-output pairs is given to the model.
- The model analyzes patterns and relationships between inputs and outputs.
- It adjusts its parameters to minimize prediction errors.
- After training, the model is tested on new data to check its accuracy.
Example: Student Marks Prediction
- Consider a dataset where input is study hours and output is marks obtained.
- Example data:
- 2 hours → 40 marks
- 4 hours → 60 marks
- 6 hours → 80 marks
- The model learns that marks increase as study hours increase.
- After training, if a student studies for 5 hours, the model can predict marks (around 70).
- This is a regression problem because the output is continuous.
Types of Supervised Learning
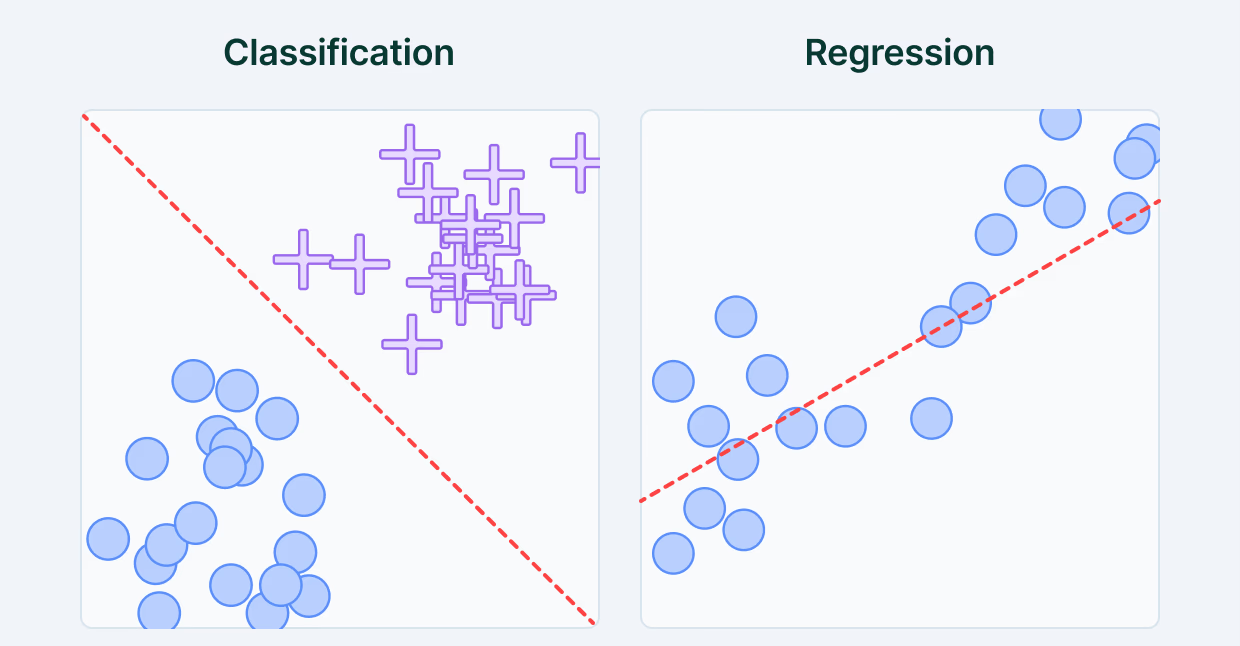
-
Classification: In classification, the output is categorical, meaning it belongs to a specific class or category. The model learns to assign input data to predefined labels.
- Example: Pass/Fail, Spam/Not Spam, Yes/No.
-
Regression: In regression, the output is continuous, meaning it can take any numerical value within a range. The model predicts a quantity based on input data.
- Example: Marks prediction, salary estimation, temperature forecasting.
Unsupervised Learning
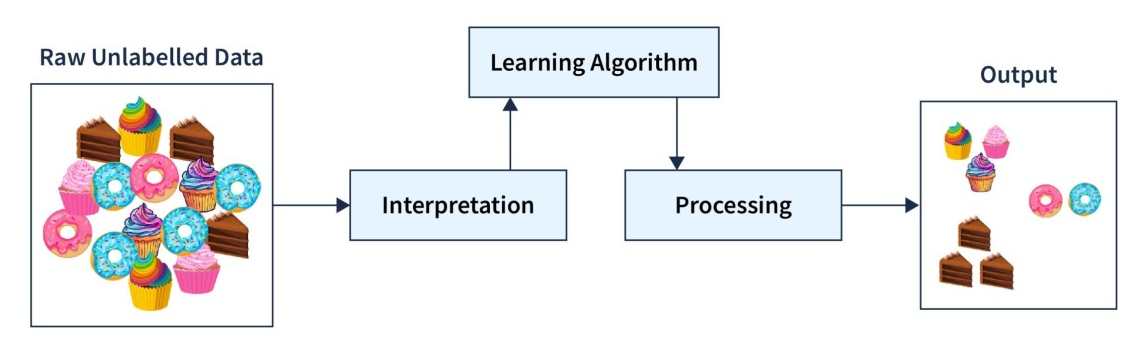
- Unsupervised Learning is a type of Machine Learning where the model is trained using unlabeled data.
- In this method, only input data is provided, and there are no predefined output labels.
- The model automatically finds hidden patterns, relationships, or structures in the data.
- It is mainly used for exploratory data analysis and pattern discovery.
- Example: Customer segmentation in marketing or grouping students based on performance patterns.
Clustering in Unsupervised Learning
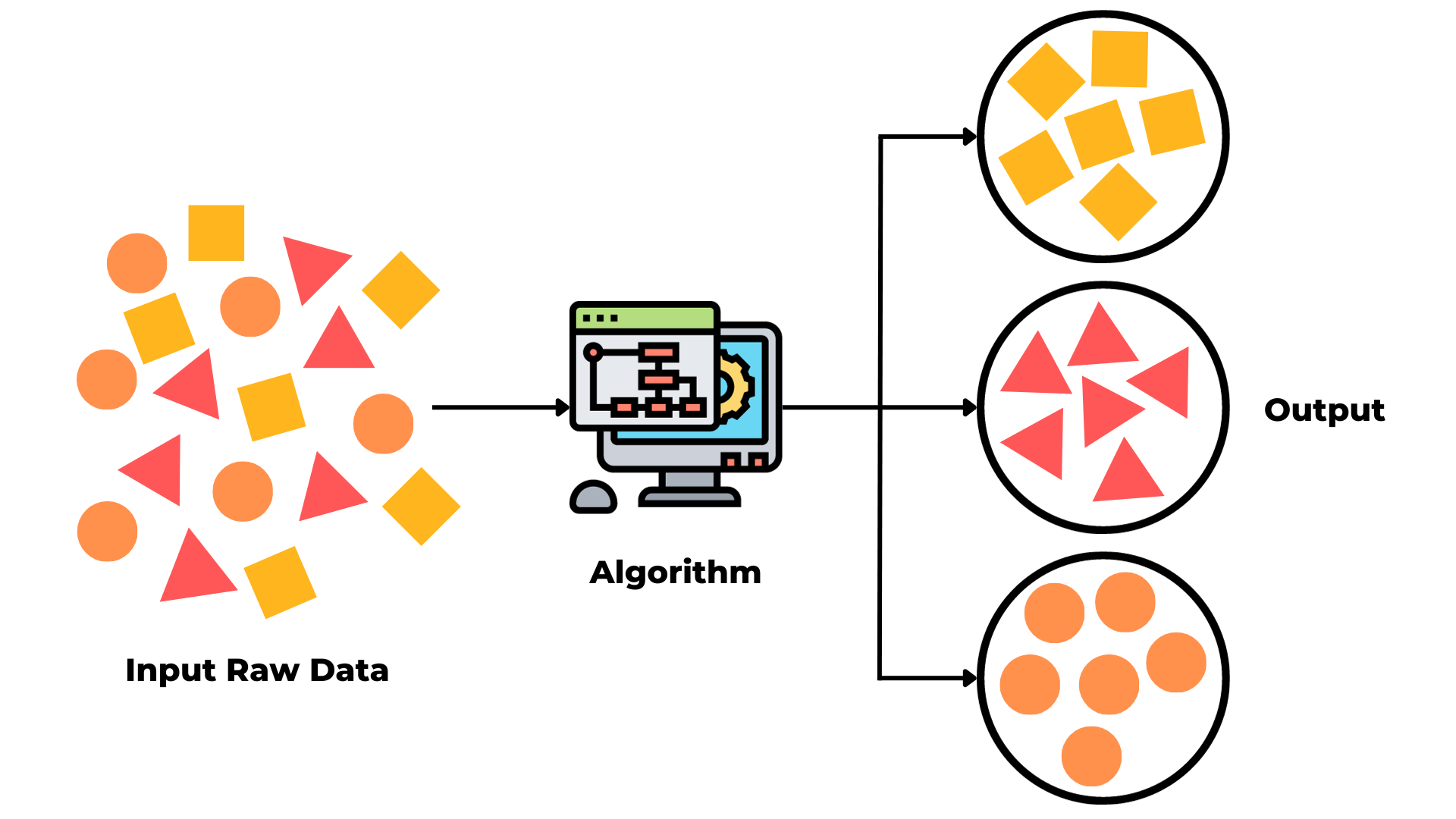
- Clustering is a technique used to group similar data points together based on their characteristics.
- The model identifies patterns and divides the data into different groups called clusters.
- Data points within the same cluster are more similar to each other than to those in other clusters.
- It is widely used in data analysis, marketing, and recommendation systems.
Practical Example: Customer Segmentation
- Consider a dataset of customers with features like age, income, and spending habits.
- There are no labels given, so the model analyzes the data and groups customers into clusters.
- Example:
- Group 1: High income, high spending customers
- Group 2: Low income, low spending customers
- Group 3: Medium income, moderate spending customers
- Businesses can use these clusters to target customers with personalized marketing strategies.
Reinforcement Learning
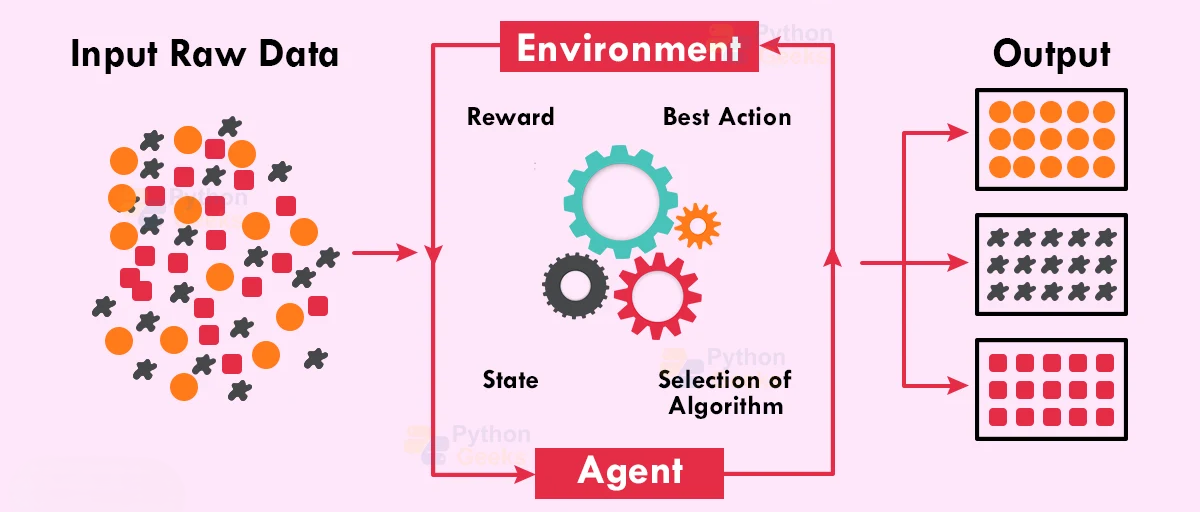
- Reinforcement Learning is a type of machine learning where an agent learns by interacting with an environment and receiving rewards or penalties based on its actions.
- The agent takes actions and receives feedback in the form of rewards or penalties.
- The goal of the agent is to learn the best actions that maximize the total reward over time.
- Learning happens through trial and error, without labeled data.
- Example: Game-playing AI like chess or self-driving cars that learn safe driving behavior.
Key Components of Reinforcement Learning
- Agent: The learner or decision-maker (e.g., game player).
- Environment: The system in which the agent operates (e.g., game board).
- Action: The choices made by the agent.
- Reward: Feedback received after taking an action (positive or negative).
- Policy: The strategy used by the agent to decide actions.
Example: Game Playing (Chess or Video Game)
- The agent plays a game by making moves (actions).
- If the agent makes a good move, it receives a positive reward.
- If it makes a wrong move or loses, it receives a negative reward (penalty).
- Over many attempts, the agent learns which moves lead to winning.
- Gradually, it improves its strategy and plays the game more efficiently.
- This learning process helps the agent develop optimal decision-making skills.
Machine Learning Workflow
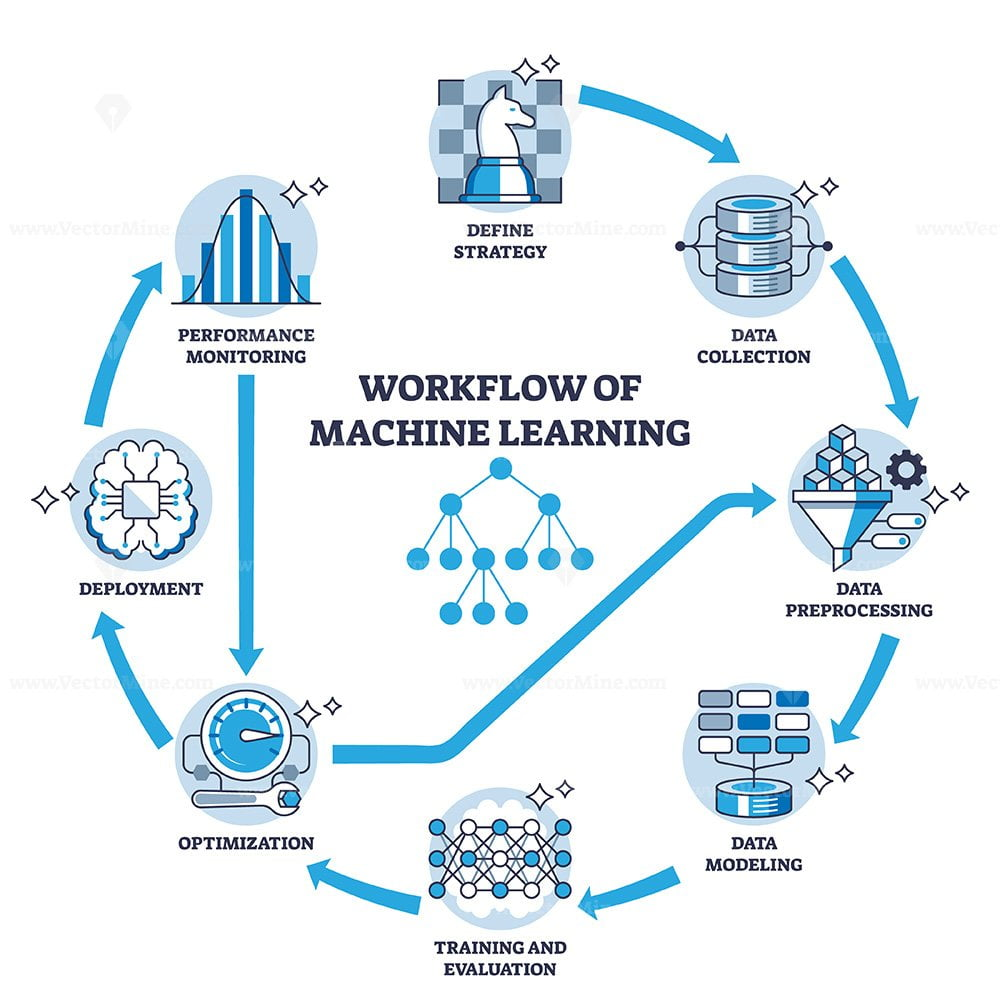
Introduction
- The Machine Learning workflow is a structured process used to build, train, and evaluate a machine learning model. Each step in the workflow is important because the performance of the final model depends on how well each stage is executed.
1. Data Collection
- Data collection is the first step in the machine learning process.
- Relevant data is gathered from sources such as databases, CSV files, sensors, websites, surveys, or APIs.
- The quality and quantity of data directly affect the performance of the model.
- Example: Collecting student attendance, study hours, and exam marks for prediction.
2. Data Pre-processing
- Raw data is usually incomplete, inconsistent, or noisy, so it must be cleaned and prepared.
- This step includes handling missing values, removing duplicates, encoding categorical data, and scaling numerical features.
- Data is also divided into training and testing datasets.
- Proper pre-processing improves model accuracy and reliability.
3. Model Training
- In this stage, a machine learning algorithm is selected and trained using the training dataset.
- The model learns patterns and relationships between input features and output labels.
- The goal is to minimize errors and improve prediction performance.
- Example: Training a model to predict whether a student will pass or fail.
4. Model Testing
- After training, the model is tested using unseen data.
- This step checks how well the model performs on new data.
- It helps identify problems such as overfitting or underfitting.
5. Model Evaluation
- The performance of the model is measured using evaluation metrics.
- Common metrics include accuracy, precision, recall, F1-score, and confusion matrix.
- Evaluation ensures the model is reliable before deployment.
6. Deployment and Prediction
- Once the model performs well, it is deployed into a real-world system.
- The model is used to make predictions on new incoming data.
- Example: Deploying a spam detection model in an email system.
Importance of Data Pre-Processing in ML
- Data pre-processing is an essential step in Machine Learning because raw data is often incomplete, inconsistent, and noisy.
- It helps in cleaning and transforming data into a suitable format for model training.
- Proper preprocessing improves the accuracy, efficiency, and reliability of the model.
- It ensures that the model learns meaningful patterns instead of incorrect or misleading information.
- Without pre-processing, the model may give poor or inaccurate results.
Techniques Used in Data Pre-Processing
1. Handling Missing Values
- Missing data occurs due to errors or incomplete data collection.
- It can be handled by removing rows/columns or replacing missing values with mean, median, or mode.
- This ensures the dataset remains complete and usable.
2. Removing Noise and Outliers
- Outliers are abnormal values that can negatively affect model performance.
- These values are detected and removed or adjusted to improve accuracy.
- Example: Extremely high salary values compared to normal range.
3. Encoding Categorical Data
- Machine Learning models understand numerical data, not text.
- Categorical values (e.g., Male/Female) are converted into numbers using encoding techniques.
- This allows the model to process and learn from the data.
4. Feature Scaling
- Different features may have different ranges, which can affect model performance.
- Scaling techniques like normalization and standardization bring values to a similar range.
- This improves the efficiency of algorithms.
5. Splitting Dataset
- The dataset is divided into training and testing sets.
- Training data is used to train the model, while testing data is used to evaluate performance.
- This helps in checking how well the model works on unseen data.
Differentiate between Training Data & Testing Data
Training Data:
- Training data is the portion of the dataset used to train the machine learning model.
- The model learns patterns, relationships, and rules from this data by adjusting its parameters.
Testing Data:
- Testing data is the portion of the dataset used to evaluate the performance of the trained model.
- It is unseen data, meaning the model has not learned from it during training.
Key Differences
- Purpose: Training data is used for learning, while testing data is used for evaluation.
- Usage: Training data helps build the model, whereas testing data checks how well the model performs.
- Data Exposure: The model has already seen training data, but testing data is completely new to the model.
- Outcome: Training improves the model, while testing measures accuracy and performance.
Why Both Are Necessary
- Training data is necessary to teach the model how to make predictions based on patterns in data.
- Testing data is necessary to check whether the model can generalize well to new, unseen data.
- Using only training data may lead to overfitting, where the model performs well on known data but poorly on new data.
- Testing ensures the model is reliable, accurate, and suitable for real-world applications.
Model Evaluation
- Model evaluation is the process of measuring how well a machine learning model performs.
- It helps in understanding whether the model is making correct predictions or not.
- Evaluation is done using different metrics that compare predicted results with actual results.
- It ensures that the model is reliable and works well on unseen data.
Accuracy
- Accuracy measures how many predictions made by the model are correct out of the total predictions.
- It gives an overall idea of the model’s performance.
- Example: If a model correctly predicts 90 out of 100 cases, its accuracy is 90%.
Precision
- Precision measures how many of the predicted positive results are actually correct.
- It focuses on the correctness of positive predictions.
- Example: Out of all emails marked as spam, how many are actually spam.
Recall
- Recall measures how many actual positive cases are correctly identified by the model.
- It focuses on capturing all real positive instances.
- Example: Out of all actual spam emails, how many were correctly detected as spam.
Steps to Install Python
1. Download Python
- Visit the official Python website (
python.org). - Download the latest stable version of Python suitable for your operating system.
2. Install Python
- Run the downloaded installer file.
- Check the option “Add Python to PATH” before clicking install.
- Click on “Install Now” and complete the installation process.
3. Verify Installation
- Open Command Prompt or Terminal.
- Type
python --versionand press Enter. - If Python is installed correctly, it will display the installed version.
Steps to Install Jupyter Notebook
1. Install pip (if not installed)
- pip is the package manager for Python.
- It usually comes pre-installed with Python.
2. Install Jupyter Notebook
- Open Command Prompt or Terminal.
- Type the command:
pip install notebook - Press Enter and wait for installation to complete.
3. Launch Jupyter Notebook
- In the terminal, type:
jupyter notebook - Press Enter, and it will open in your default web browser.
4. Create a New Notebook
- Click on “New” and select “Python 3”.
- A new notebook will open where you can write and run code.
5. Install Required Libraries
- Install important libraries for Machine Learning using pip:
pip install numpypip install pandaspip install matplotlibpip install scikit-learn
NumPy
- NumPy is a powerful Python library used for numerical computing and working with multi-dimensional arrays.
- It provides fast and efficient operations on large datasets, which are essential in Machine Learning.
Role of NumPy in Machine Learning
- NumPy plays an important role in Machine Learning because ML algorithms work with numerical data.
- It is used for data preprocessing such as reshaping, filtering, and transforming data.
- It supports mathematical operations such as linear algebra, statistical operations, and matrix multiplication.
- Most ML libraries like Pandas, Scikit-learn, TensorFlow, and Keras are built on top of NumPy.
- It helps in handling large datasets efficiently and improves computation speed.
Commonly Used NumPy Functions
1. Creating Arrays
np.array()is used to create an array from a list or tuple.np.arange()is used to create a sequence of numbers.np.zeros()creates an array filled with zeros.np.ones()creates an array filled with ones.np.eye()creates an identity matrix.
2. Array Properties
arr.ndim()is used to find the number of dimensions of an array.arr.shape()gives the size of each dimension.arr.reshape()changes the shape of the array.
3. Mathematical Functions
np.min()returns the minimum value.np.max()returns the maximum value.np.sum()calculates the sum of elements.np.mean()calculates the average.np.sqrt()calculates the square root.
4. Sorting and Filtering
np.sort()sorts the elements of an array.np.unique()returns unique values from an array.- Boolean indexing is used to filter elements based on conditions.
Importance of NumPy in Machine Learning
1. Efficient Data Storage
- NumPy provides ndarray, which stores large amounts of data in a compact and efficient format.
- It is more memory-efficient than Python lists.
2. Fast Computation
- NumPy performs mathematical and statistical operations very quickly due to optimized implementation.
- This improves the speed of Machine Learning algorithms.
3. Mathematical Operations
- It supports operations like addition, multiplication, mean, and standard deviation, which are widely used in ML models.
4. Data Preprocessing
- NumPy is used to clean, reshape, and transform data before training a model.
- It helps in preparing data in the correct format.
5. Integration with ML Libraries
- NumPy works seamlessly with libraries like Pandas, Matplotlib, and Scikit-learn.
- Most Machine Learning tools depend on NumPy arrays.
Simple Example
- Suppose we have data of student marks:
[40, 60, 80] - Using NumPy, we can easily calculate the average marks:
import numpy as np
marks = np.array([40, 60, 80])
average = np.mean(marks)
print(average) # 60Pandas
- Pandas is an open-source Python library used for data manipulation and data analysis. It provides powerful and flexible data structures that make working with structured data easy and efficient.
What is Pandas
- Pandas is mainly used to handle and analyze tabular data.
- It provides two main data structures called Series and DataFrame.
- A Series is a one-dimensional labeled array.
- A DataFrame is a two-dimensional table consisting of rows and columns.
- Pandas is widely used in data science, Machine Learning, finance, and research.
Importance of Pandas in Data Analysis
- Pandas helps in cleaning and preparing raw data before analysis.
- It allows easy handling of missing values and duplicate data.
- It supports data filtering, sorting, and grouping operations.
- It can read data from various sources such as CSV files, Excel files, and databases.
- It integrates well with other libraries such as NumPy, Matplotlib, and Scikit-learn.
- It simplifies complex data manipulation tasks with simple syntax.
Major Functions of Pandas
1. Data Creation
pd.Series()is used to create a Series.pd.DataFrame()is used to create a DataFrame.
2. Reading and Writing Data
pd.read_csv()reads data from a CSV file.pd.read_excel()reads data from an Excel file.df.to_csv()writes data to a CSV file.
3. Data Inspection
df.head()displays the first few rows.df.tail()displays the last few rows.df.info()provides summary information about the dataset.df.describe()shows statistical summary.
4. Data Cleaning
df.drop()removes rows or columns.df.fillna()fills missing values.df.drop_duplicates()removes duplicate records.
5. Data Manipulation
df.sort_values()sorts data.df.groupby()groups data based on a column.df.merge()combines two datasets.df.filter()filters data based on conditions.
Use of Pandas in Data Pre-Processing
- Pandas is widely used in Machine Learning to clean, organize, and prepare raw data for analysis.
- It provides powerful tools to handle missing values, remove duplicates, filter data, and transform datasets.
- Pandas makes data preprocessing simple and efficient using DataFrame operations.
Common Preprocessing Tasks using Pandas
1. Handling Missing Values
- Missing values can be filled or removed using functions like
fillna()anddropna().
2. Removing Duplicates
- Duplicate records can be removed using
drop_duplicates()to ensure data quality.
3. Data Filtering
- Specific data can be selected using conditions to focus on relevant information.
4. Data Transformation
- Columns can be modified or new columns can be created for better analysis.
5. Reading and Writing Data
- Pandas can load data from CSV, Excel, and other formats using
read_csv().
Small Example
import pandas as pd
# Create a sample dataset
data = {
"Name": ["A", "B", "C", "D"],
"Marks": [80, None, 70, 90]
}
df = pd.DataFrame(data)
# Fill missing values with average
df["Marks"].fillna(df["Marks"].mean(), inplace=True)
# Display cleaned data
print(df)- In this example, Pandas is used to handle missing values by replacing them with the average marks.
- This makes the dataset complete and ready for Machine Learning.
Matplotlib
- Matplotlib is an open-source Python library used for data visualization. It helps in creating charts, graphs, and plots to represent data visually. Visualization makes it easier to understand patterns, trends, and relationships in data.
What is Matplotlib
- Matplotlib is mainly used to create static, animated, and interactive visualizations in Python.
- It works well with NumPy and Pandas for plotting numerical and tabular data.
- The most commonly used module in Matplotlib is pyplot.
- It is widely used in data analysis, Machine Learning, and scientific research.
Importance of Matplotlib in Data Visualization
- It helps in understanding data through graphical representation.
- It makes complex data easier to interpret.
- It supports various types of charts for analysis.
- It is useful for presenting insights clearly in reports and dashboards.
- It helps in identifying trends, patterns, and outliers.
Commonly Used Functions of Matplotlib
1. Line Plot
plt.plot()is used to create line graphs.- Useful for showing trends over time.
2. Bar Chart
plt.bar()is used to create bar charts.- Useful for comparing categories.
3. Histogram
plt.hist()is used to show frequency distribution of data.
4. Scatter Plot
plt.scatter()is used to show the relationship between two variables.
5. Pie Chart
plt.pie()is used to represent data in percentage form.
6. Titles and Labels
plt.title()adds a title to the graph.plt.xlabel()andplt.ylabel()add labels to axes.plt.legend()adds a legend to the graph.
7. Displaying the Plot
plt.show()is used to display the final graph.
Scikit-learn
- Scikit-learn is a popular Python library used to build and apply machine learning models.
- It provides simple and efficient tools for data pre-processing, model training, testing, and evaluation.
Uses of Scikit-learn
- Train models like Linear Regression, Decision Trees, and KNN.
- Split data into training and testing sets.
- Evaluate model performance using metrics like accuracy.
- Perform pre-processing tasks like scaling and encoding.
Example
from sklearn.linear_model import LinearRegression
# Sample data
X = [[1], [2], [3], [4]]
y = [10, 20, 30, 40]
# Create and train model
model = LinearRegression()
model.fit(X, y)
# Predict value
prediction = model.predict([[5]])
print(prediction)- This example shows how Scikit-learn is used to train a model and make predictions.